Abstract.
This work addresses issues concerning the informational content of library websites and examines the main sections of small library websites. A web library in software is a distributed knowledge system in the digital informational space featuring an evolving intelligent search. The study presents research findings on the potential of applying semantic text models through the use of conceptual graphs as objects for storing electronic libraries.
Keywords:
web-library, library web-site, search, information resource, information system, electronic catalog.
Introduction and Context
In the digital era, libraries are undergoing a profound transformation. Traditional libraries are shifting into digital platforms, driven by rapid advancements in digital technologies. This evolution necessitates a rethinking of how information is stored, processed, and retrieved. In this context, ontologies have emerged as a key tool. By modeling knowledge semantically, ontologies structure data to enable quick and intuitive searches, improving both the interactivity of library systems and the accuracy of search results. The subject matter of this study is timely, given the challenges of managing an ever-growing volume of digital information and the demand for personalized user experiences.
Research Problem and Objectives
The central issue explored is the enhancement of efficiency and usability in modern digital web libraries. Traditional search methods, which rely solely on keyword matching, often fall short because they ignore context, semantic relationships, and the diverse needs of users. The problem is twofold: users must be able to navigate a vast informational space easily, and the search results must be both relevant and comprehensive.
To address these challenges, the primary objective of the study is to develop an electronic public library system that serves both academic and artistic communities. This system is envisioned to include a robust, ontology-based search mechanism that goes beyond basic keyword matching. Instead, it leverages semantic text models and conceptual graphs to capture the deeper meaning embedded within texts, thereby meeting the nuanced needs of users—referred to as “readers.”
Methodological Framework
The research employs conceptual graphs as a framework to represent the semantic models of texts within a web library. Conceptual graphs capture the core ideas of sentences and texts by identifying central concepts (or themes) and mapping the relationships among them. This approach allows for:
• Automated Catalog Construction: By analyzing streams of incoming text, the system can automatically modify and correct library catalogs, enabling efficient aggregation and clustering of information.
• Knowledge Extraction: The system extracts key concepts and ontologies from electronic documents, which then serve as a foundation for organizing library resources.
A unique challenge addressed is the inherent ambiguity in language. Since a conceptual graph is meant to represent the content of a sentence, it cannot be constructed in an entirely unambiguous way. To mitigate this, the study introduces the concept of a “central concept” (or theme), which helps to standardize the representation of content across different texts. Furthermore, the research explores hierarchical clustering—grouping conceptual graphs into clusters based on thematic similarity—using methods from evolutionary computation and genetic algorithms.
Key Components of Web Libraries
The study provides a detailed analysis of the ecosystem of web libraries. It categorizes the various elements involved:
• Objects:
These include literary works, metadata, books, audiobooks, translated editions, film adaptations, presentations, journals, periodicals, electronic editions, and multiple types of collections (open access, subscription-based, or restricted). Additional objects comprise web services, subscriptions, catalogs, classifiers, indexes, and various library sections (ranging from local studies and history to modern literature and children’s books).
• Subjects:
The users (readers) of web libraries are characterized by demographic factors (such as age), search queries, access levels, historical interactions, and specific interests. This category also includes different types of readers—such as buyers, subscribers, and event participants—as well as personal accounts.
• Administrators and Moderators:
Responsible for managing the library system, these individuals handle user verification, set access privileges, organize searches, maintain data integrity, update collections, moderate content, and engage in outreach activities (such as webinars, virtual tours, and surveys).
• Informational Resources:
• These resources include detailed descriptions of information storage, ontologies and thesauri, structural models of data storage (defining units and objects), and the informational models that underpin the search and retrieval systems. They also cover bibliographic and abstracting resources, which are essential for the electronic library’s search functionality.
• User Interface (SEB):
The website acts as an intelligent interface, focusing on the semantics of user queries rather than their mere structure. It supports the formalization of queries, the construction of new relational links (even through random graphs), deep search methods using neural networks, and the interpretation of fuzzy or metaphorical queries. The system is designed to facilitate a dialogue between users, ensuring that the search process is both intuitive and adaptive.
Results and Discussion
A significant contribution of the research is the development of an ontology of artistic images. This ontology captures not only the visual or literal representation of artistic elements but also their deeper meaning—how an artistic image is interpreted within a specific communicative context. The study distinguishes several types of images, including:
• Character Images: Such as heroes, lyrical figures, or collective representations.
• Landscape, Interior, and Symbolic Images: Each carrying its own set of aesthetic and semantic nuances.
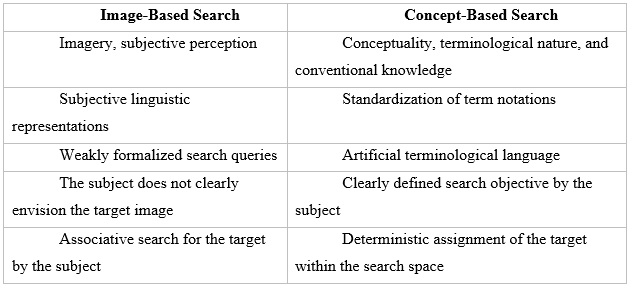
Additionally, the research outlines a detailed classification of artistic literature into genres (epic, lyrical, dramatic) and further sub-categories based on form, content, and literary movements. It compares image-based search methods (which rely on subjective, associative processes) with concept-based searches (which are more systematic and computationally driven). This comparison underscores the potential benefits of adopting an ontologically driven approach, which standardizes terminology and ensures that search goals are clearly defined.
Practical Implications
The study’s findings have several practical applications:
• Enhanced Search Accuracy: By integrating semantic models and ontologies, the system improves the relevance of search results and reduces the effort required by users to locate information.
• Catalog Automation: The use of conceptual graphs and clustering algorithms can automate the organization and updating of library catalogs, making it easier to manage large volumes of data.
• Personalization and Adaptability: The proposed system supports personalized search experiences, adapting to the specific needs and interests of individual users.
• Integration with External Data: The research highlights the importance of connecting web libraries with external data sources, thereby broadening the scope and utility of the library system.
Conclusion
In summary, the research demonstrates that a web library of artistic literature—built upon an ontological foundation—can be viewed as an evolving distributed knowledge system. The integration of semantic search capabilities, facilitated by conceptual graphs and advanced clustering techniques, not only enhances the user experience but also supports efficient information management. The findings pave the way for the creation of more sophisticated web applications that can serve libraries of varying complexity, ultimately contributing to the broader goal of democratizing access to knowledge and cultural heritage.
Literature
The following information sources were used for the analysis:
1. Noy, N. F., & McGuinness, D. L. (2001). Ontology Development 101: A Guide to Creating Your First Ontology. Stanford University.
https://protege.stanford.edu/publications/ontology_development/ontology101-noy-mcguinness.html
2. Heath, T., & Bizer, C. (2011). Linked Data: Evolving the Web into a Global Data Space. Morgan & Claypool Publishers.
https://www.morganclaypool.com/doi/abs/10.2200/S00334ED1V01Y201105ICR014
3. Allemang, D., & Hendler, J. (2008). Semantic Web for the Working Ontologist. Morgan Kaufmann Publishers.
https://www.amazon.com/Semantic-Web-Working-Ontologist-Effective/dp/0123859654
4. Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to Information Retrieval. Cambridge University Press.
https://nlp.stanford.edu/IR-book/
5. Borgman, C. L. (2000). From Gutenberg to the Global Information Infrastructure: Access to Information in the Networked World. MIT Press.
https://mitpress.mit.edu/9780262523455/from-gutenberg-to-the-global-information-infrastructure/
|