Нормалізація - один з найважливіших етапів проектування бази даних, оскільки нормалізована структура полегшує внесення змін у базу даних, так як нові дані можна інтегрувати без необхідності переробляти всю систему, що є вагомим аспектом у контексті бізнесу.
Пошук функціональних залежностей (далі ФЗ) є ключовим аспектом процесу нормалізації баз даних, оскільки саме вони визначають, як атрибути в таблицях пов’язані між собою. [1, c. 1]
Для кращого розуміння суті ФЗ розглянемо детальніше визначення:
Відношення R задовольняє ФЗ X → Y (де X, Y ⊆ R) тоді і тільки тоді, коли для будь-яких кортежів t1, t2 ∈ R виконується: якщо t1[X] = t2[X], то t1[Y] = t2[Y]. У такому випадку кажуть, що X (детермінант, або визначальна множина атрибутів) функціонально визначає Y (залежна множина).
На базі даного визначення ми можемо використати головні умови відношення та виконати пошук за допомогою алгоритма FA (Functional Dependency Analysis), що включає в себе такі кроки:
1. Перебирає всі можливі комбінації атрибутів як визначальні.
2. Для кожної комбінації перевіряє, які атрибути є залежними.
3. Формує множину всіх знайдених залежностей.
Однак висока складність даного алгоритму має у гіршому випадку експоненціальний час виконання, оскільки кількість комбінацій атрибутів зростає дуже швидко, що не є досить ефективно.
Ставлячи перед собою задачу пошуку ФЗ для аналізу великих наборів даних з меншою складністю, у порівнянні з повним перебором, одним з найкращих рішень буде вибір алгоритм TANE (Template-Based Algorithm for Discovering Dependencies) з наступним принципом роботи [2, c. 100]:
1. Створення всіх можливих комбінацій атрибутів.
2. Сортування та аналіз кожної комбінації для виявлення залежностей.
3. Здійснення перевірок можливих порушень залежності при додаванні нових атрибутів.
Також, якщо говорити про великі обсяги даних, варто відзначити, що одним з ефективних підходів для виявлення ФЗ є алгоритм FD Mine. Цей алгоритм призначений для автоматизованого пошуку ФЗ у великих наборах даних, що особливо важливо в умовах, коли ручний аналіз вимагає значних затрат часу і ресурсів.
Алгоритм FD Mine базується на принципах інтелектуального аналізу даних та використовує методи, які дозволяють зменшити обчислювальні витрати при обробці великих масивів інформації. Завдяки своїй ефективності та здатності обробляти дані різного формату, FD Mine знаходить широке застосування в таких галузях, як бізнес-аналітика, наукові дослідження та управління даними [3, c. 3].
Кроки реалізації алгоритму FD Mine:
1. Розділ даних на невеликі підмножини.
2. У кожній підмножині пошук залежності, після чого - об’єднання результатів.
3. Застосування мінімізації на підсумкових залежностях.
Алгоритм Гудмана - ще один з методів для виявлення ФЗ у реляційних базах даних. Він був розроблений для автоматизації процесу аналізу даних та має на меті підвищити ефективність виявлення зв’язків між атрибутами. Нижче представлений детальніший опис цього алгоритму:
1. Формування кортежів та визначення потенційних залежностей
2. Використання принципу гомоморфізму.
3. Формалізація залежностей та оцінка надійності.
Для практичного порівняння алгоритмів візьмемо відкриту базу даних на 16 тисяч записів Sakila, розроблена для демонстрації функціональності MySQL, що містить дані про кінофільми, акторів, клієнтів та інші елементи, пов'язані з орендою фільмів.
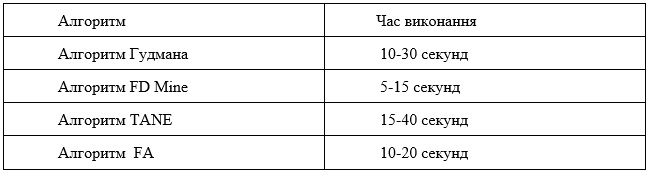
Візуальна часова оцінка результатів роботи алгоритмів, розглянутих вище вказана в таблиці 1:
Таблиця 1
У ході проведеного аналізу алгоритмів було визначено, що різні алгоритми демонструють різну ефективність залежно від обсягу та структури даних. Алгоритм FD Mine виявився найшвидшим і найефективнішим для роботи з великими обсягами даних, що робить його оптимальним вибором для сучасних інформаційних систем. Алгоритм Гудмана показав хороші результати для середніх наборів даних, в той час як FA також виявився продуктивним, проте дещо повільнішим у порівнянні з FD Mine. Алгоритм TANE, хоча й є потужним інструментом для виявлення функціональних залежностей, вимагає більше часу на обробку, що може обмежити його застосування в сценаріях з великими наборами даних.
Таким чином, вибір алгоритму залежить від конкретних потреб проекту, обсягу даних і вимог до швидкості виконання. Розуміння переваг і недоліків кожного алгоритму дозволить спеціалістам більш ефективно виконувати завдання з нормалізації бази даних та оптимізації структур даних. Це, в свою чергу, позитивно позначиться на продуктивності інформаційних систем та якості прийнятих рішень.
Список літератури
1. Wang D. Z. Functional dependency generation and applications in pay-as-you-go data integration systems / D. Z. Wang, L. Dong, A. D. Sarma, M. Franklin, A. Halevy.
2. Tane: An Efficient Algorithm for Discovering Functional and Approximate dependencies [Electronic Resource] / Y. Huntala, J. Karkkainen, P. Porkka, H. Toivonen, The Computer journal, vol. 42, no. 2, 1999.
3. FD_Mine: Discovering Functional Dependencies in a Database Using Equivalences / Hong Yao, H. J.Hamilton, C. J.Butz.
|