На сьогоднішній день зі збільшенням обсягів та доступності документів у цифровій формі та подальшої необхідності їх упорядкування, особливого значення набули техніки автоматизованої та напівавтоматизованої класифікації текстів за попередньо визначеними категоріями.
Текстові дані є одними із найпоширеніших типів даних, але оскільки вони не мають чіткої структури, процес вилучення інформації з них може бути досить складним та тривалим. Робота з текстовими даними відноситься до обробки природної мови (NLP), однієї з підгалузей штучного інтелекту. Класифікація тексту в NLP – це операція, яка призначає мітки (категорії) певному тексту, для того, щоб автоматично групувати, структурувати та класифікувати будь-який тип документа, повідомлення, дослідження, файлу або веб-вмісту [1].
На рис. 1 зображено класичний процес класифікації тексту. Проте, варто зазначити, що залежно від характерних особливостей різних методів класифікації, він буде дещо видозмінюватись.
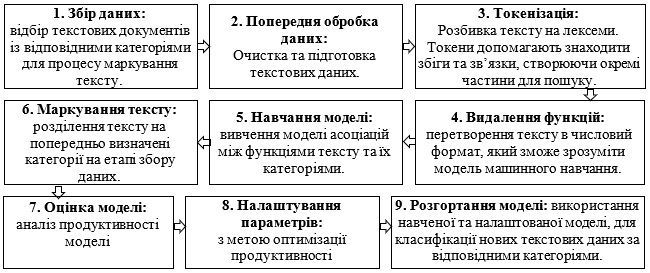
Рис. 1. Процес класифікації тексту
Примітка. Розроблено автором на основі даних джерел [1, 2]
На сьогодні, найпоширенішими системами класифікації текстів є:
1. Класифікація тексту на основі правил – даний метод використовує попередньо визначені правила для класифікації текстових даних у різні класи або категорії. Цей підхід передбачає створення правил на основі конкретних ознак або шаблонів у тексті для точної класифікації. Таким чином, коли новий текст вводиться як вхідні дані для моделі, модель визначатиме відповідну категорію на основі правил, створених раніше. Даний метод є досить точним, проте створення відповідних правил потребує глибокого аналізу та численних тестувань, які забирають багато часу. Також цей метод не масштабується, і його важко підтримувати, оскільки нові дані потребують нових правил, які в свою чергу можуть вплинути на вже наявні дані [3].
2. Системи машинного навчання – передбачають алгоритми, які навчаються класифікувати на основі минулих спостережень через навчання з попередньо позначеними прикладами. Ці системи навчаються розпізнавати асоціації між фрагментами тексту та призначати певну категорію (мітку) певному введеному тексту. Машинне навчання класифікації тексту має дві фази – навчання та прогнозування. Під час фази навчання контрольований алгоритм навчається на наборі даних із вхідними мітками. Наприкінці даного процесу отримується навчена модель, яка використовується для отримання прогнозів (міток) щодо нових та невідомих даних. Коли модель машинного навчання завершила навчання, її можна використовувати для прогнозування міток нових і невідомих даних. Цей метод перевершує точність підходу, що базується на правилах і здатний за рахунок навчання розпізнавати нові категорії [4].
Наприклад: якщо необхідно прокласифікувати дані за двома чи більше групами (правозахисні неурядові організації, молодіжні, екологічні, економічні, благодійні, тощо), необхідно визначити списки слів (ознак), пов’язаних із кожною групою. Згодом, коли будуть вводиться нові дані, система буде підраховувати кількість слів (ознак), пов’язаних із кожною групою та, відповідно їх класифікувати.
Варто відмітити, що результати класифікації на основі машинного навчання будуть задовільними лише тоді, коли базуватимуться на достатній кількості вхідних даних хорошої якості.
Серед найбільш використовуваних методів машинного навчання є:
- метод Байєсової (наївної) класифікації (Naive Bayes) – це ймовірнісний алгоритм, заснований на теоремі Байєса. Це простий і ефективний метод, який часто використовується для завдань класифікації тексту. Даний метод обчислює ймовірність належності документа до кожної категорії на основі появи в ньому слів та вибирає категорію з найвищою ймовірністю як класифікацію;
- метод опорних векторів (SVM) – є надійним універсальним алгоритмом, який використовується для двійкової та багатокласової класифікації тексту. Він спрямований на пошук оптимальної гіперплощини, яка найкраще розділяє точки даних на різні класи;
- штучні нейронні моделі – передбачає згорткові (CNN) та рекурентні нейронні мережі (RNN), які можуть вловлювати складні шаблони в текстових даних. CNN використовують згорткові шари для виявлення шаблонів у локальних текстових послідовностях. RNN обробляють текст послідовно, фіксуючи залежності між словами. Обидва типи мереж навчаються на позначених даних, щоб вивчати представлення документів для класифікації.
- дерево рішень (DTs) – алгоритм машинного навчання, який створює деревоподібну структуру вузлів і листів рішень. Кожен вузол перевіряє наявність слова, що допомагає вивчати шаблони в текстових даних.
Кількість неурядових організацій в Україні зростає. Науковці досліджують, як правило, всю сукупність організацій громадянського суспільства в цілому, є окремі роботи, які охоплюють певні сфери: молодіжні, правозахисні організації, наукова спільнота проявляє інтерес до діяльності неурядових організацій в економічній сфері, разом з тим відсутнє відповідне комплексне дослідження. Використання напівавтоматизованих методів, як один із способів уточнення класифікації неурядових організацій за сферами їх діяльності сприятиме дослідженням в даній сфері, адже ці методи можуть забезпечити вирішення проблеми доступу до кількісних даних про діяльність неурядових організацій, а саме їх спеціалізації за сферою, які недоступні з офіційних статистичних джерел.
Власне, алгоритми класифікації тексту є основою автоматизованої категоризації документів і відіграють важливу роль у різноманітних завданнях обробки природної мови. Розуміння сильних сторін і обмежень цих алгоритмів має важливе значення для ефективного застосування їх до завдань класифікації. Коректний алгоритм може підвищити точність категоризації та класифікації, що є тематикою подальших досліджень у контексті виокремлення неурядових організацій, які підтримують розвиток підприємництва серед загальної кількості таких організацій в Україні.
Список літератури:
1. Alper Kursat Uysal. An improved global feature selection scheme for text classification. Expert Systems with Applications. 2016. Vol. 43. P. 82-92.
2. Litofcenko J., Karner D., Maier F. Methods for Classifying Nonprofit Organizations According to their Field of Activity: A Report on Semi-automated Methods Based on Text. VOLUNTAS: International Journal of Voluntary and Nonprofit Organizations. 2020. P. 227-237.
3. Волосюк Ю. В. Методи класифікації текстових документів в задачах Text mining. Наукові записки Українського науково-дослідного інституту зв’язку. 2014. №6 (34). С. 76-81.
4. Голуб Т.В., Зеленьова І.Я., Грушко С.С., Луценко Н.В. Програмна реалізація автоматичного класифікатора текстів на основі уточненого методу формування простору ознак категорій. Телекомунікаційні та інформаційні технології. 2020. № 1 (66). С. 227-237.
|






